Introduction
We’ve covered off prepping and installing K8s on this blog a few different ways; with VM templates built manually, with cloud-init, and with ClusterAPI vSphere. Let’s say you’ve grown attached to some of the workloads you’re running on one of your clusters, naturally. It would be nice to backup and restore those should something go wrong - or even, as was my case, I deployed a distro of K8s on my Raspberry Pi cluster that I wasn’t wild about and wanted to move to another - how do you migrate those workloads?
Enter Velero ↗. Velero (formerly Heptio Ark) is a backup, restore and DR orchestration application for your K8s workloads. In this post i’d like to take you through the installation and use of Velero, as well as some test backup and restores so you can kick the tyres on your own clusters and maybe give the team some feedback!
I’m assuming you have a K8s cluster up and running with a working storage system. I mean, otherwise you’d have nothing to back up. If not - check the blogs mentioned above to get one running.
If you just want to see it running - check out my VMWorld session ↗ and go to 19:30
Prerequisites
Tools
I am using macOS, so will be using the brew package manager to install and manage my tools, if you are using Linux or Windows, use the appropriate install guide for each tool, according to your OS.
For each tool I will list the brew install command and the link to the install instructions for other OSes.
- brew
- git -
brew install git - helm -
brew install kubernetes-helm - kubectl -
brew install kubernetes-cli
Installation and Use Workflow
To get Velero running on our cluster there are a few steps we need to run through, at a high level (explaination on these components in a bit):
- Download and install the Velero CLI to our local machine
- Install Minio on our cluster for use as a backup repo
- Install Velero on our cluster
Installation
Velero CLI
The Velero CLI isn’t strictly required but it handles a lot of the heavy lifting of creating Velero specific custom resources (CRDs) in K8s that you’d have to do manually otherwise, things like backup schedules and all that jazz.
The Velero CLI is pre-compiled and available for download on the Velero GitHub page ↗, as stated before i’m running macOS so i’ll download and move the binary into my PATH (adjust this to suit your OS).
wget https://github.com/vmware-tanzu/velero/releases/download/v1.1.0/velero-v1.1.0-darwin-amd64.tar.gz
tar -zxvf velero-v1.1.0-darwin-amd64.tar.gz
mv velero-v1.1.0-darwin-amd64/velero /usr/local/bin/.
As long as /usr/local/bin is in your PATH, you’ll be able to now run the CLI:
$ velero version
Client:
Version: v1.1.0
Git commit: a357f21aec6b39a8244dd23e469cc4519f1fe608
<error getting server version: the server could not find the requested resource (post serverstatusrequests.velero.io)>
The error is expected as we haven’t yet installed Velero into our cluster - but it shows that the CLI is working. An important thing to note is that when using the Velero CLI, it uses the currently active K8s cluster that’s in your terminal session.
Installing Minio
Velero uses S3 API-compatible object storage as its backup location, that means to create a backup we need something that exposes and S3 API. Minio is a small, easy to deploy S3 object store you can run on-prem.
For this example, we’re going to run Minio on our K8s cluster, in production you’d want your S3 store somewhere else, for reasons that should be obvious.
To install Minio we’re going to use helm ↗ which is a package manager for K8s - this simplifies the installation down to creating a yaml file for the configuration.
Let’s create the yaml file for the setup of Minio with helm (a full list of variables can be found on the chart page in the repo ↗):
$ cat minio.yaml
image:
tag: latest
accessKey: "minio"
secretKey: "minio123"
service:
type: LoadBalancer
defaultBucket:
enabled: true
name: velero
persistence:
size: 50G
Stepping through this, it will deploy the latest version of Minio available, set the username and password to minio and minio123 respectively, expose the service using a LoadBalancer (consequently, you’ll need a LoadBalancer of some kind in your cluster - I recommend MetalLB ↗ for labs). Next up, we tell it to automatically create a bucket called velero and to persist the data in a 50GB volume.
Ideally, instead of using Service Type LoadBalancer - you’d use an Ingress Controller like Traefik ↗ or NginX ↗, but that’s the subject for another blog post - an LB will do for a proof of concept.
I’m assuming you have the file saved as minio.yaml - so let’s now use helm to deploy this to our cluster.
helm install stable/minio --name minio --namespace infra -f minio.yaml
This installs Minio to your cluster, in a namespace called infra and the helm deployment is given a name of minio (otherwise you’ll get a randomly allocated name).
If we run the following, we’ll get the IP and Port that Minio will be accessible on outside the cluster - in my case the IP is 10.198.26.3 and is accessible on port 9000:
$ kubectl get service minio -n infra
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
minio LoadBalancer 10.110.94.210 10.198.26.3 9000:32549/TCP 127m
If you substitute your own details into the below and login using minio and minio123 you’ll see the Minio UI with the Velero bucket present.
open http://10.198.26.3:9000
Ta-da, an S3 compliant object store, running on K8s.
Installing Velero
Velero can be installed either via a helm chart or via the Velero CLI, my preferred method is to use the helm chart as it means I can store the configuration in a yaml file and deploy it repeatably without having to memorise commands.
If you want to deploy via the CLI, see the Velero documentation ↗, we are going to use helm here.
Again, as with the Minio chart, the first step is to create the configuration yaml file:
$ cat velero.yaml
image:
tag: v1.1.0
configuration:
provider: aws
backupStorageLocation:
name: aws
bucket: velero
config:
region: minio
s3ForcePathStyle: true
publicUrl: http://10.198.26.3:9000
s3Url: http://minio.infra.svc:9000
credentials:
useSecret: true
secretContents:
cloud: |
[default]
aws_access_key_id = minio
aws_secret_access_key = minio123
snapshotsEnabled: false
configMaps:
restic-restore-action-config:
labels:
velero.io/plugin-config: ""
velero.io/restic: RestoreItemAction
data:
image: gcr.io/heptio-images/velero-restic-restore-helper:v1.1.0
deployRestic: true
So, it may look a little strange with the provider type aws and such, but that is simply there to allow us to use the S3 backup target - notice that we just use the IP address and port of the Minio service we deployed in the previous step as the URL to send the backups to.
One thing i’d like to call out is the difference between publicUrl and s3Url - publicUrl is what the Velero CLI will communicate with when it needs to get things like logs and such, the s3Url is what the Velero in-cluster process sends the data and logs to. In this case s3Url is not publically accessible, it uses a Kubernetes in-cluster DNS record (minio.infra.svc:9000) - this says, send the data to service minio in namespace infra and of type service on port 9000.
Because the s3Url is only resolvable within the K8s cluster, we must also specify the publicUrl to allow the CLI to also interface with the assets in that object store.
The last line may be something you’re wondering about - deployRestic tells Velero to deploy the restic ↗ data mover to pull bits off the disk from inside the cluster, rather than relying on native snapshotting and diff capabilities and is required for vSphere installations.
With all that said, once you’ve adjusted the above to suit your environment (likely just publicUrl and s3Url) you can deploy the helm chart.
helm install stable/velero --name velero --namespace velero -f velero.yaml
With Velero deployed to our cluster, we can now get to creating some backup schedules and test how it all works.
Deploying a Sample Application
As of Velero v1.1.0, CSI volumes are supported, meaning we can backup the contents of PVs on kubernetes clusters running CSI plugins, as well as the manifests that make up that app.
To test this out, let’s deploy an app - a Slack clone i’m awfully fond of called RocketChat ↗ - as usual, we’ll create the config yaml file first:
$ cat rocketchat.yaml
persistence:
enabled: true
service:
type: LoadBalancer
mongodb:
mongodbPassword: password
mongodbRootPassword: password
This will deploy RocketChat (which uses MongoDB as a database) to our cluster and expose it using another LoadBalancer IP - again, ideally this would be done using an Ingress Controller instead, but for simplicity - we’ll do it this way.
helm install stable/rocketchat --name rocketchat --namespace rocketchat -f rocketchat.yaml
If you watch the pods as this comes up, you should see the arbiter, the primary and then the secondary MongoDB nodes come up, following that - the RocketChat app itself will come up and at that point, will be accessible within the browser:
kubectl get pod -n rocketchat -w
Once all the pods show Running and 1/1 - we can grab the LoadBalancer IP and port and access the app:
$ kubectl get svc -n rocketchat
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
rocketchat-mongodb ClusterIP 10.102.96.222 <none> 27017/TCP 3m34s
rocketchat-mongodb-headless ClusterIP None <none> 27017/TCP 3m34s
rocketchat-rocketchat LoadBalancer 10.106.105.16 10.198.26.4 80:30904/TCP 3m34s
So, to access this service, as with Minio - sub in your own IP into the following:
open http://10.198.26.4
Go through the motions of creating a user account with whatever name and password you like until you get to the main page:
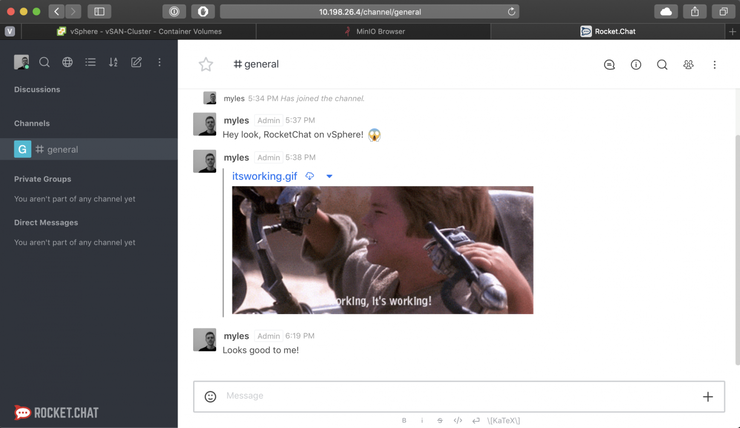
Navigate to the #general channel and upload something or type in some text - this will be the data we want to protect with Velero!
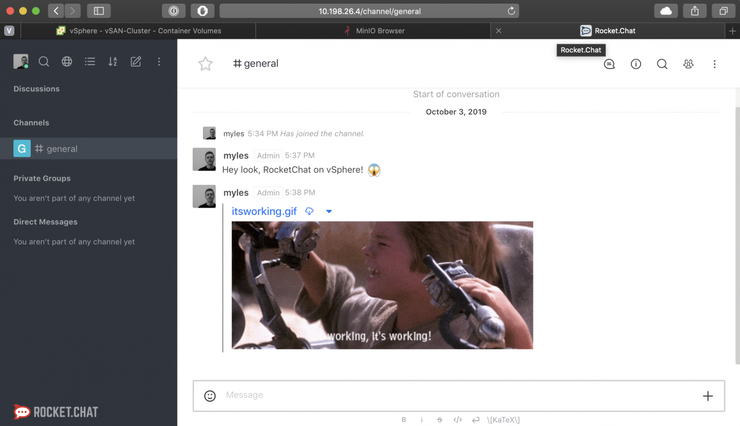
Now, we can’t have that data going missing - i’m sure you’ll agree, so let’s back it up with Velero!
Backup and Restore with Velero
Now that we have an application, and data we want to protect - let’s tag the PersistentVolumes so Velero will back them up. First - we need to find out what the volumes are called:
$ kubectl get pvc -n rocketchat
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
datadir-rocketchat-mongodb-primary-0 Bound pvc-dda3e972-e5fa-11e9-a30e-00505691513e 8Gi RWO space-efficient 23m
datadir-rocketchat-mongodb-secondary-0 Bound pvc-ddb17d70-e5fa-11e9-a30e-00505691513e 8Gi RWO space-efficient 23m
rocketchat-rocketchat Bound pvc-dd633f78-e5fa-11e9-a30e-00505691513e 8Gi RWO space-efficient 23m
The first word in the name of each PVC, is the name of the volume - so datadir and rocketchat. Let’s tell Velero to backup those datadir volumes by tagging the pods.
$ kubectl annotate pod -n rocketchat --selector=release=rocketchat,app=mongodb backup.velero.io/backup-volumes=datadir --overwrite
pod/rocketchat-mongodb-arbiter-0 annotated
pod/rocketchat-mongodb-primary-0 annotated
pod/rocketchat-mongodb-secondary-0 annotated
The above command looks for all pods in the rocketchat namespace with the tags release=rocketchat and app=mongodb and annotates them with a label backup.velero.io/backup-volumes=datadir - this tells Velero to backup the Persistent Volumes that are consumed with the name datadir.
Set up a Velero Schedule
Now that our app is set up to request Velero backups - let’s schedule some - in the below example, we are asking for a backup to be taken every hour and for them to be held for 24 hours each.
velero schedule create hourly --schedule="@every 1h" --ttl 24h0m0s
Let’s create another that runs daily and retains the backups for 7 days:
velero schedule create daily --schedule="@every 24h" --ttl 168h0m0s
If we query Velero, we can now see what schedules are set up:
$ velero get schedules
NAME STATUS CREATED SCHEDULE BACKUP TTL LAST BACKUP SELECTOR
daily Enabled 2019-10-03 17:57:43 +0100 BST @every 24h 168h0m0s 23s ago <none>
hourly Enabled 2019-10-03 17:56:20 +0100 BST @every 1h 24h0m0s 1m ago <none>
Additionally, we can see they’ve already taken a backup each, we can query those backups with the following command:
$ velero get backups
NAME STATUS CREATED EXPIRES STORAGE LOCATION SELECTOR
daily-20191003165757 Completed 2019-10-03 17:58:33 +0100 BST 6d default <none>
hourly-20191003165634 Completed 2019-10-03 17:56:34 +0100 BST 23h default <none>
If we wanted to take an ad-hoc backup that can be achieved through the following (in this case, we will only backup the rocketchat namespace):
$ velero backup create before-disaster --include-namespaces rocketchat
Backup request "before-disaster" submitted successfully.
Run `velero backup describe before-disaster` or `velero backup logs before-disaster` for more details.
As the command says - we can query progress with the following:
velero backup describe before-disaster --details
Adding the --details option will show us the restic backup status of the persistent volumes at the very bottom:
Restic Backups:
Completed:
rocketchat/rocketchat-mongodb-primary-0: datadir
rocketchat/rocketchat-mongodb-secondary-0: datadir
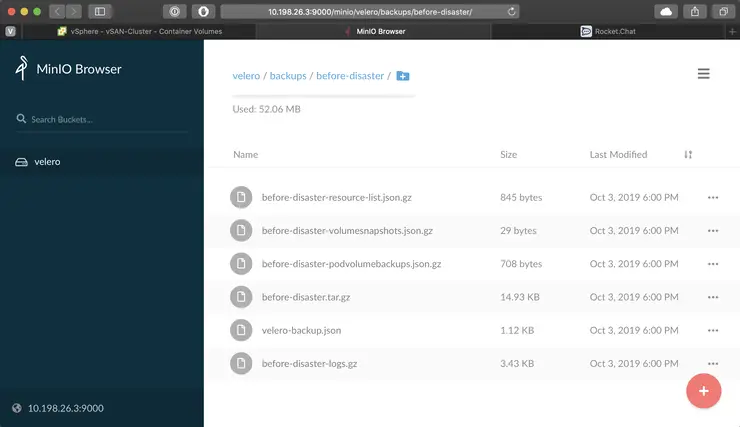
And now if we go to Minio, in the velero bucket you will see the backups and their contents (they are all encrypted on disk by default):
open http://10.198.26.3:9000/minio/velero/backups/before-disaster/
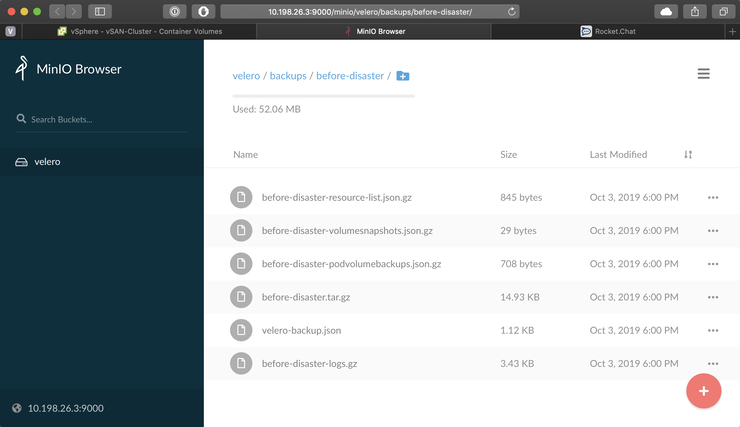
Simulating a disaster
Now that we have a backup and some scheduled backups, let’s delete the rocketchat app - and all it’s data off disk and restore it using Velero.
helm delete --purge rocketchat
This will delete the RocketChat app - but because MongoDB uses a StatefulSet, the data volumes will stick around - as you can see from the CNS UI:
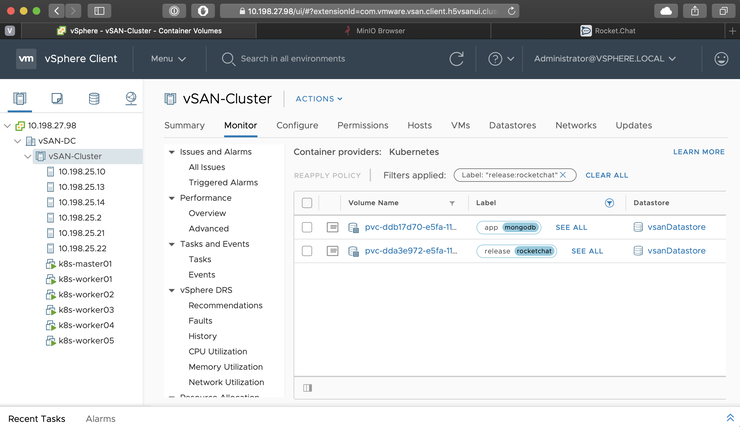
We can delete these PVs by deleting the namespace too:
kubectl delete ns rocketchat
So, now all our data is truely gone - as evidenced by the CNS UI no longer showing any volumes for the rocketchat filter:
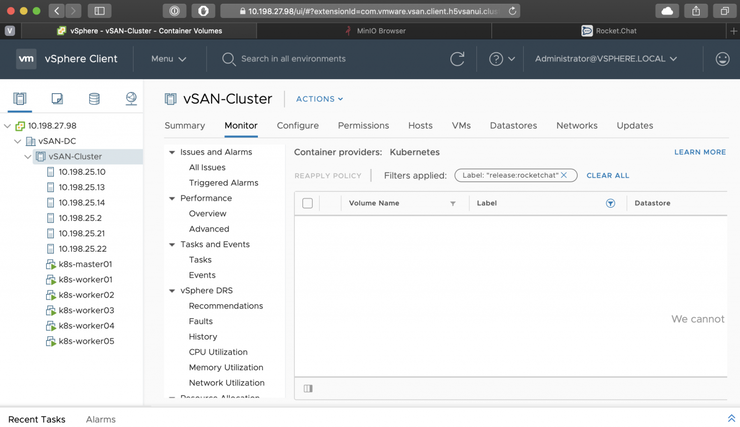
Restoring with Velero
Our app is dead, and the data is gone - so it’s time to restore it from one of the backups we took - i’ll use the ad-hoc one for ease of naming:
$ velero restore create --from-backup before-disaster --include-namespaces rocketchat
Restore request "before-disaster-20191003181320" submitted successfully.
Run `velero restore describe before-disaster-20191003181320` or `velero restore logs before-disaster-20191003181320` for more details.
Again - let’s monitor it with the command from above:
velero restore describe before-disaster-20191003181320 --details
Once the output of the command shows completed and the Restic Restores at the bottom are done, like below, we can check on our app:
Name: before-disaster-20191003181320
Namespace: velero
Labels: <none>
Annotations: <none>
Phase: Completed
Backup: before-disaster
Namespaces:
Included: rocketchat
Excluded: <none>
Resources:
Included: *
Excluded: nodes, events, events.events.k8s.io, backups.velero.io, restores.velero.io, resticrepositories.velero.io
Cluster-scoped: auto
Namespace mappings: <none>
Label selector: <none>
Restore PVs: auto
Restic Restores:
Completed:
rocketchat/rocketchat-mongodb-primary-0: datadir
rocketchat/rocketchat-mongodb-secondary-0: datadir
Let’s see if the pods are back up and running, and our PVCs are restored in our namespace:
$ kubectl get po,pvc -n rocketchat
NAME READY STATUS RESTARTS AGE
pod/rocketchat-mongodb-arbiter-0 1/1 Running 0 3m5s
pod/rocketchat-mongodb-primary-0 1/1 Running 0 3m5s
pod/rocketchat-mongodb-secondary-0 1/1 Running 0 3m5s
pod/rocketchat-rocketchat-7bdf95cb47-86q9t 1/1 Running 0 3m4s
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
persistentvolumeclaim/datadir-rocketchat-mongodb-primary-0 Bound pvc-1d90d0d7-e601-11e9-a30e-00505691513e 8Gi RWO space-efficient 3m5s
persistentvolumeclaim/datadir-rocketchat-mongodb-secondary-0 Bound pvc-1d95abc7-e601-11e9-a30e-00505691513e 8Gi RWO space-efficient 3m5s
persistentvolumeclaim/rocketchat-rocketchat Bound pvc-1d99ea27-e601-11e9-a30e-00505691513e 8Gi RWO space-efficient 3m5s
In the CNS UI - we’ll see the volumes again present - this time with some extra velero labels against them:
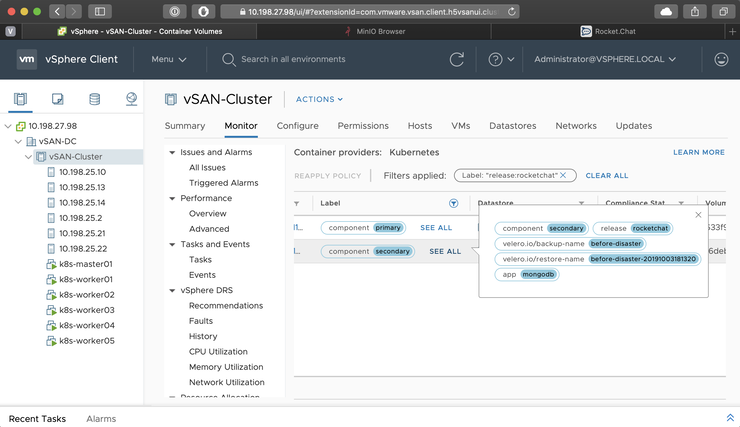
And our app should once be again accessible and our data safe:
open http://10.198.26.4
Troubleshooting
A tip on troubleshooting Velero backups - make liberal use of the logs command:
velero restore logs before-disaster-20191003181320
This is where the publicUrl section from the very start matters - if you don’t have that populated, your logs won’t get displayed to you, so if you’re experiencing that, make sure you’ve defined that parameter.
The logs have a trove of information in them, so if Restic is having trouble pulling data from a volume or such, all that info is in there!
This brings us to the end of our look at Velero on vSphere - and in particular the integration with CSI. If you have feedback for the Velero team - please reach out on GitHub ↗ and file some issues, whether is enhancements, bugs - or if you just need help. Stay tuned for more K8s goodness in the near future!
Why not follow @mylesagray on Twitter ↗ for more like this!