As of late, I have been getting my feet wet in more networking things - Firstly out of necessity, but it has grown into a genuine area of interest to me. I have a homelab that I like to simulate a production working environment in, so I had a nice opportunity to lab up what a possible multi-tenant IaaS architecture might look like using NSX.
NSX fundamentally changes how customer environments for service providers are designed - it moves the complexity away from the physical network and up into the hypervisor management layer, let’s be honest anything that limits touching the physical infra is good, right? The complexity is not gone - it still exists, but now it is easily automate-able. More automation = less human error.
Firstly, it allows for very easy automation for setup and modification of an entire customer platform through the use of NSX, vCenter, vCloud Director and their respective APIs and if applicable, upstream switches (NX-OS API for example) and secondly, it protects against a misconfiguration taking down an entire environment…
Who has ever forgotten add in switchport trunk vlan allow add [number]…?
Right - let’s move on :)
Challenges
If we think about a traditional service provider network and the challenges associated with it, there is usually high-touch on shared networking components (Top of Rack switches, routers, firewalls) this critical infrastructure is typically highly regulated and controlled due to the non-standard nature of the changes and the impact they may have. We can address this risk in some ways, Change Approval Boards (CABs), shadowing and other measures. All these factors have an effect on the cost of operating the service, ability to address demand and general customer experience and satisfaction.
Process Flow
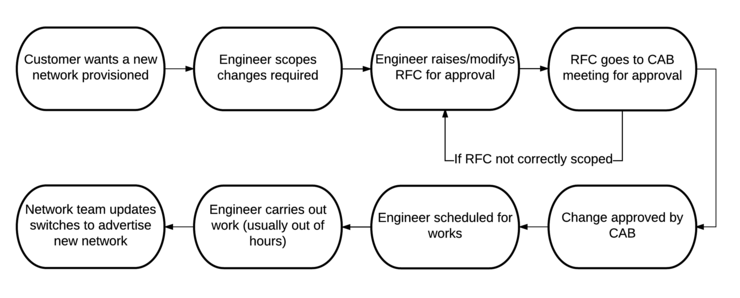
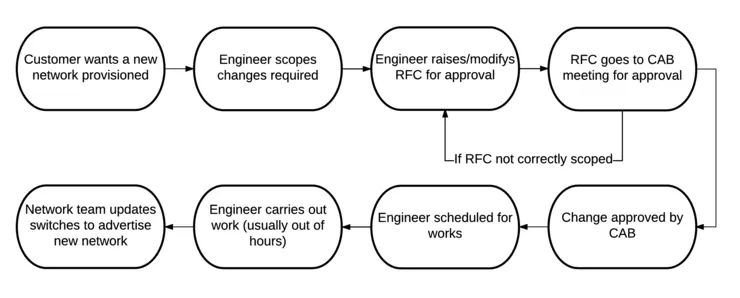
A procedure for an operation (like for example, when you want to add a subnet to a customer’s network) goes something like the following. It would need to be scoped, a request for change would need to be drawn up by the engineer, it would need to run through a CAB meeting for approval, it would need scheduled (typically out of hours due to risk mitigation), the engineer would need to execute and there may even be a tie-in with the network team/MPLS provider to advertise that subnet from the site to the rest of their network - which in turn would likely have its change control process. This process all adds further delays, cost and risk.
To achieve the level of agility such that a customer could log into for example a web portal, provision a new VM, as well as its associated network and, have that available across all their sites and services instantly, is not something that exists in such an environment.
Solutions
What happens when you change this environment from one where individual components that support multiple customers are modified - to one that; uses a set, unchanging config for the underlying shared infrastructure? Instead of changing the common components, the services that run on top of that infrastructure are customer specific and operate in a pre-determined manner? This predictability means that these changes can be executed without much if any lead time. Predictability and automation mitigate risk due to changes being uniform and templated and relaxes regulation to the point where no change control for the above actions is required.
Moving to an SDN approach also has the advantage of allowing some things that are not possible, or may just be possible with very specialist kit and engineers in a traditional multi-tenant network setting.
If for example, you have two datacenters (primary and DR), and you need to invoke a DR action on a subset - or indeed the whole infrastructure. In the physical networking world, it is very costly and operationally intensive to make sure configuration is mirrored on each site (think firewall rules, policies, routes, services) and kept up to date with the possibly rapidly changing landscape of the primary site, not to mention the chance of human error.
When using SDN - in particular, I will call out NSX, things like Firewall Rules are bound to VMs and are replicated across sites, so if you do a partial failover, the traffic is still policed as it were on the primary site with no extra configuration. If you do a full site failover, and you are using dynamic routing that advertises routes northbound to a corporate network, when using NSX these routes can be auto-populated as subnets become active inside the virtual infrastructure on the DR site.
That is what I hope to achieve with this blog series - prove that software defined is the way to go for virtualised datacenter workloads when used in a service provider setting through simple demonstrations of what is achievable with this technology.
Why not follow @mylesagray on Twitter ↗ for more like this!