Introduction
If you want to learn about the basics and key concepts of ClusterAPI, then check out my post on the Alpha back in June here - it covers the high level concepts and troubleshooting of ClusterAPI, as well as what it offers to you as a user who wants to set up Kubernetes.
This blog is a look at what has changed and how you can use ClusterAPI to deploy K8s clusters on vSphere that use CNS and the CSI plugin for storage, that was introduced as part of vSphere 6.7 U3 ↗. If you want a video overview of CNS and CSI, check out my YouTube video here ↗.
Prerequisites
Tools
I am using macOS, so will be using the brew package manager to install and manage my tools, if you are using Linux or Windows, use the appropriate install guide for each tool, according to your OS.
For each tool I will list the brew install command and the link to the install instructions for other OSes.
- brew
- git -
brew install git - go -
brew install go - govc -
brew tap govmomi/tap/govc && brew install govmomi/tap/govc - kubectl -
brew install kubernetes-cli - kind (Kubernetes-in-Docker) - No brew installer yet
- clusterctl
Clusterctl installation
clusterctl is built currently as part of ClusterAPI upstream, so can be downloaded from there ↗:
curl -Lo ./clusterctl-darwin-amd64 https://github.com/kubernetes-sigs/cluster-api/releases/download/v0.2.4/clusterctl-darwin-amd64
chmod +x ./clusterctl-darwin-amd64
mv clusterctl-darwin-amd64 /usr/local/bin/clusterctl
Kind installation
kind hasn’t been bundled into brew, yet - so we need to install it the old-fashioned way (this is for macOS, as an example):
curl -Lo ./kind-darwin-amd64 https://github.com/kubernetes-sigs/kind/releases/download/v0.5.1/kind-darwin-amd64
chmod +x ./kind-darwin-amd64
mv ./kind-darwin-amd64 /usr/local/bin/kind
Environment Setup
The first thing we need is to ensure your vSphere environment is on 6.7 U3, CSI depends on the CNS API in vCenter, which is only present in 6.7 U3 and higher.
Pull down the OS image
The next thing we need to do is pull down the guest OS image that will be deployed to build our K8s cluster. The CAPV team have built a number of images for K8s that you can choose from here ↗.
A point of note - if you are using 6.7U3 and wish to use CSI/CNS - then you need to ensure the VMHW (aka the VMX version) is at 13 or higher, this is done by default on images in the table on the above link that are on K8s v1.15.4 and above, so it is recommended you use one of those. If not, you can always upgrade the template post deploy as in the getting started guide ↗.
The images come in two flavours currently, CentOS and Ubuntu, i’m downloading and using an Ubuntu 18.04 version with K8s v1.15.4:
wget https://storage.googleapis.com/capv-images/release/v1.15.4/ubuntu-1804-kube-v1.15.4.ova -P ~/Downloads/
Set up vSphere with govc
Fill in the appropriate environment variables for your vSphere environment to allow us to connect with govc (I put this in a file called govcvars.sh):
export GOVC_INSECURE=1
export GOVC_URL=vc01.satm.eng.vmware.com
export GOVC_USERNAME=administrator@vsphere.local
export GOVC_PASSWORD=P@ssw0rd
export GOVC_DATASTORE=vsanDatastore
export GOVC_NETWORK="Cluster01-LAN-1-Routable"
export GOVC_RESOURCE_POOL='cluster01/Resources'
export GOVC_DATACENTER=DC01
Import the env vars into our shell and connect to the vCenter with govc:
source govcvars.sh
govc about
Now that we’re connected to vCenter, let’s create some folders for our templates and cluster VMs to live in:
govc folder.create /$GOVC_DATACENTER/vm/Templates
govc folder.create /$GOVC_DATACENTER/vm/Testing
govc folder.create /$GOVC_DATACENTER/vm/Testing/K8s
Customise and import the template VM
There have been some changes to the OVA and OVF image building process, so if you followed along last time - this is slightly different now. Let’s extract the OVF spec from the template and change the Network to the name of your Port Group in vSphere and MarkAsTemplate to true as that’s what it’s going to end up as anyway - may as well do it on import!
Because we left the Name parameter as null, it will automatically be named ubuntu-1804-kube-v1.15.4) and we will use that name for the rest of this blog, so if you changed Name keep and eye out and change those as we go along.
govc import.spec ~/Downloads/ubuntu-1804-kube-v1.15.4.ova | python -m json.tool > ubuntu.json
Edit the ubuntu.json to reflect your preferences:
{
"DiskProvisioning": "thin",
"IPAllocationPolicy": "dhcpPolicy",
"IPProtocol": "IPv4",
"NetworkMapping": [
{
"Name": "nic0",
"Network": "Cluster01-LAN-1-Routable"
}
],
"Annotation": "Cluster API vSphere image - Ubuntu 18.04 and Kubernetes v1.15.4 - https://github.com/kubernetes-sigs/cluster-api-provider-vsphere/tree/master/build/images",
"MarkAsTemplate": true,
"PowerOn": false,
"InjectOvfEnv": false,
"WaitForIP": false,
"Name": null
}
Let’s import the template we just downloaded into VC and the folder that we just created:
govc import.ova -folder /$GOVC_DATACENTER/vm/Templates -options ubuntu.json ~/Downloads/ubuntu-1804-kube-v1.15.4.ova
Using ClusterAPI
During the Alpha, we had to build clusterctl from source - no longer! If you followed the instructions above, you should have clusterctl available in your PATH so the following command should show you the help output:
clusterctl -h
Management Cluster
Define your K8s Cluster Specification
Creating cluster manifests has also changed and is much simpler now, all built into a Docker container for us to use.
So, let’s define where our cluster should be deployed, the name of it, K8s version, what SSH keys should be added to the guest’s trusted store and how many resources it should have by filling in the following environment variables (I put the below in a file called envvars.txt) - change the below to suit your environment:
cat <<EOF >envvars.txt
# K8s attributes
export KUBERNETES_VERSION='1.15.4'
# vSphere attributes
export VSPHERE_USERNAME=administrator@vsphere.local
export VSPHERE_PASSWORD=P@ssw0rd
export VSPHERE_SERVER=vc01.satm.eng.vmware.com
# vSphere deployment configs
export VSPHERE_DATACENTER=DC01
export VSPHERE_DATASTORE=vsanDatastore
export VSPHERE_NETWORK="Cluster01-LAN-1-Routable"
export VSPHERE_RESOURCE_POOL="cluster01/Resources/CAPV"
export VSPHERE_FOLDER="/DC01/vm/Testing/K8s"
export VSPHERE_TEMPLATE="ubuntu-1804-kube-v1.15.4"
export VSPHERE_DISK_GIB=60
export VSPHERE_NUM_CPUS="2"
export VSPHERE_MEM_MIB="2048"
export SSH_AUTHORIZED_KEY='ssh-rsa AAAAB3......w== myles@vmware.com'
EOF
Let’s create the manifest files that will define and create our cluster when we plug them into clusterctl:
docker run --rm \
-v "$(pwd)":/out \
-v "$(pwd)/envvars.txt":/envvars.txt:ro \
gcr.io/cluster-api-provider-vsphere/release/manifests:latest \
-c management-cluster
This has placed the yaml files in a new directory ./out, so let’s use clusterctl to spin up a brand new management K8s cluster:
Create the Management Cluster
The below command plugs in the manifest files created above in order to define our CAPV management cluster - you can change the yaml files from above to suit your liking, or change things in the command like the name of the cluster.
clusterctl create cluster \
--bootstrap-type kind \
--bootstrap-flags name=capv-cluster-mgmt-01 \
--cluster ./out/management-cluster/cluster.yaml \
--machines ./out/management-cluster/controlplane.yaml \
--provider-components ./out/management-cluster/provider-components.yaml \
--addon-components ./out/management-cluster/addons.yaml \
--kubeconfig-out ./out/management-cluster/kubeconfig
This will take in the order of 5-10 minutes depending on your environment, it will create a kind single node K8s cluster on your local machine within a Docker container to act as a bootstrap.
It then creates another single-node K8s VM on your target vSphere environment with the same configuration, and deletes the kind cluster from your local machine, because it was only there to act as a bootstrap.
At this point, clusterctl will spit out the kubeconfig for your management cluster into the ./out/management-cluster/kubeconfig directory and you should be able to connect to your ClusterAPI “management” cluster:
Export the newly downloaded kubeconfig file so it’s the default for kubectl to use:
export KUBECONFIG=./out/management-cluster/kubeconfig
Check to see that the ClusterAPI items have been created (i.e. one cluster and one machine) for the management cluster.
kubectl get clusters
kubectl get machines
Workload Clusters
Define your Workload Cluster Specification
With the ClusterAPI management cluster deployed, we can now use it, along with kubectl to create other K8s workload clusters!
The workload clusters use much the same process as the management cluster, however it makes sense to look into the yaml files generated in order to do things like define the number of worker nodes and such.
This time we’ll create some more manifests for our workload cluster (note the name workload-cluster-01):
docker run --rm \
-v "$(pwd)":/out \
-v "$(pwd)/envvars.txt":/envvars.txt:ro \
gcr.io/cluster-api-provider-vsphere/release/manifests:latest \
-c workload-cluster-01
If you check out the yaml files that were generated, in particular check out the machinedeployment.yaml file and adjust the number of replicas in the MachineDeployment section as below - this would give you 3 worker nodes in your cluster, instead of the default 1:
apiVersion: cluster.x-k8s.io/v1alpha2
kind: MachineDeployment
metadata:
labels:
cluster.x-k8s.io/cluster-name: workload-cluster-01
name: workload-cluster-01-md-0
namespace: default
spec:
replicas: 3
Create the Workload Cluster
Let’s use the ClusterAPI management cluster to create our new workload cluster - we do this by passing in the yaml that was just generated to the management cluster, the ClusterAPI controller within the management cluster will then look at the specifications for each and create a new K8s cluster with the number of masters and workers as defined in controlplane.yaml and machinedeployment.yaml files respectively.
First, let’s export KUBECONFIG so we are interacting with the management cluster:
export KUBECONFIG=./out/management-cluster/kubeconfig
Next, let’s import the yaml files that define the workload cluster:
kubectl apply -f ./out/workload-cluster-01/cluster.yaml -f ./out/workload-cluster-01/controlplane.yaml -f ./out/workload-cluster-01/machinedeployment.yaml
If we watch ClusterAPI’s machines CRD we can see that it will have created a master and three workers if you changed the yaml to my change as above. This will take a few minutes, so it’s best to run this command and wait until all machines show Running.
kubectl get machines -w
Once all the machines are Running we will be able to pull down the kubeconfig for that cluster so we can deploy workloads on to it.
Connecting to the Workload Cluster
We’ve successfully provisioned our workload cluster, but how do we access and use it?
Good question, when using ClusterAPI to spin up workload clusters, it needs to put the access credentials (i.e. the kubeconfig file) somewhere, so it puts them in a K8s secret, luckily they are very easy to retrieve and decode to your local machine.
kubectl get secret workload-cluster-01-kubeconfig -o=jsonpath='{.data.value}' | { base64 -d 2>/dev/null || base64 -D; } >./out/workload-cluster-01/kubeconfig
Notice the workload-cluster-01-kubeconfig secret - this is what we want to connect to our workload cluster, it’s very easy to extract and pull this to your local machine. The command pulls the secret value which is base64 encoded in K8s - decodes it from base64 to text and creates a new kubeconfig file in the workload cluster’s directory on your laptop.
Let’s apply the addons to our workload cluster (these are mainly just the networking overlay, Calico) - required to let pods talk to one-another - we will first change clusters by exporting KUBECONFIG once again:
export KUBECONFIG=./out/workload-cluster-01/kubeconfig
kubectl apply -f ./out/workload-cluster-01/addons.yaml
And watch as the pods get spun up, when it’s all working - everything should list as Running:.
kubectl get pods -n kube-system -w
Deploy some applications
Now that the workload cluster is set up, we can deploy some apps to it - because ClusterAPI also takes care of the CSI setup, we can even deploy ones that use persistent storage!
We’re going to deploy use helm to set up an application called RocketChat on the cluster, which uses two persistent volumes, one for config and one for its MongoDB database.
Configure helm
Be aware this installation style for helm (granting the tiller pod cluster-admin privileges) is a big security no-no ↗ and is just for ease of setup here. For more information on why this is bad, look here ↗, and please don’t do this on a production cluster.
In this case, it is a throwaway cluster for me, so I will be using these permissions. First create the RBAC role and permissions for the helm service account in another new file called helm-rbac.yaml:
$ cat <<EOF >helm-rbac.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: tiller
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: tiller
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: tiller
namespace: kube-system
EOF
Apply the role to the cluster:
kubectl apply -f helm-rbac.yaml
Let’s install helm onto the cluster with the service account we provisioned:
helm init --service-account tiller
Configure a StorageClass
We’re going to delete the default StorageClass that gets deployed and instead, create our own that uses the CSI plugin that is installed by default with CAPV.
kubectl delete sc --all
Create a new StorageClass yaml that uses the CSI provisioner (and by extension, CNS) - note the provisioner line:
$ cat <<EOF >sc.yaml
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: standard
annotations:
storageclass.kubernetes.io/is-default-class: "true"
provisioner: csi.vsphere.vmware.com
parameters:
storagePolicyName: "vSAN Default Storage Policy"
EOF
The above StorageClass uses the vSAN Default Storage Policy within vCenter, but you can change it to your own - the name of the SC in this case is standard and we’ll use it deploying a demo app next.
kubectl apply -f sc.yaml
Provision an application
We’re now in a place where we can provision an application, we’re going to use helm to install RocketChat, as discussed above - RocketChat is basically an Open-Source Slack clone that you can run on-prem.
The below command tells helm to install RocketChat from the stable/rocketchat repository, give it a name, set the passwords for MongoDB and most critically - use the standard StorageClass that we just imported into the workload cluster to back the PersistentVolumes requested by RocketChat:
helm install stable/rocketchat --set persistence.StorageClass=standard,mongodb.mongodbPassword=password,mongodb.mongodbRootPassword=password
Verify the volumes got provisioned (this will take a minute before it returns back the “Bound” status):
$ kubectl get pv,pvc
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
persistentvolume/pvc-3c754fc9-f7bb-448f-8f2c-510fedc0cebc 8Gi RWO Delete Bound default/datadir-exacerbated-squirrel-mongodb-secondary-0 standard 19h
persistentvolume/pvc-47ad5e4d-4cdd-4c14-9148-5e9a2321bb8e 8Gi RWO Delete Bound default/datadir-exacerbated-squirrel-mongodb-primary-0 standard 19h
NAMESPACE NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
default persistentvolumeclaim/datadir-exacerbated-squirrel-mongodb-primary-0 Bound pvc-47ad5e4d-4cdd-4c14-9148-5e9a2321bb8e 8Gi RWO standard 19h
default persistentvolumeclaim/datadir-exacerbated-squirrel-mongodb-secondary-0 Bound pvc-3c754fc9-f7bb-448f-8f2c-510fedc0cebc 8Gi RWO standard 19h
And the pods for the application should be running:
$ kubectl get po
NAME READY STATUS RESTARTS AGE
exacerbated-squirrel-mongodb-arbiter-0 1/1 Running 0 19h
exacerbated-squirrel-mongodb-primary-0 1/1 Running 0 19h
exacerbated-squirrel-mongodb-secondary-0 1/1 Running 0 19h
exacerbated-squirrel-rocketchat-958b577d-v8vzp 1/1 Running 0 19h
At this point, we can access the application by port-forwarding to the rocketchat-rocketchat-* pod from the output above (change this to suit your pod name):
kubectl -port-forward exacerbated-squirrel-rocketchat-958b577d-v8vzp 8888:3000
Access the application on localhost:8888 in your web browser:
open http://localhost:8888
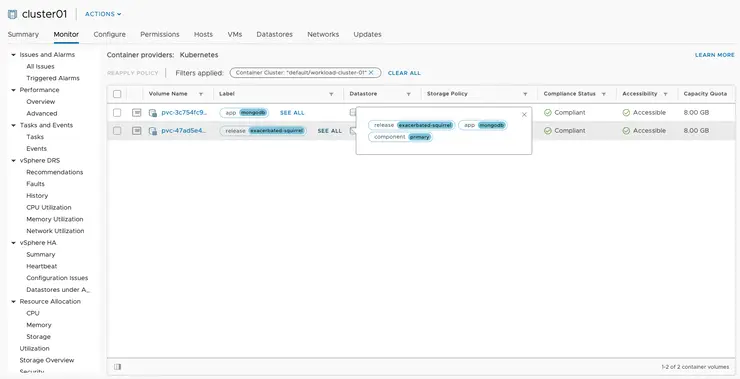
In the new CNS UI within vSphere 6.7 U3 - we can see the volumes that have been deployed from this K8s cluster via the CSI plugin:
Why not follow @mylesagray on Twitter for more like this!